

全面解析 RAG(Retrieval-Augmented Generation)
日期:2024-11-29
RAG 將檢索(Retrieval)與生成(Generation)相結合的 AI 框架,能透過檢索外部知識來增強生成模型的回答能力。
RAG 的特色
檢索外部知識
RAG 能利用外部數據庫(如文檔庫或向量數據庫)檢索與查詢相關的資訊,而不僅依賴模型內部的預訓練知識。生成專業回答
結合檢索到的上下文內容,生成模型可生成更準確且有針對性的回答。動態更新
外部知識庫的內容可持續更新,無需重新訓練模型。
RAG 的運作原理
RAG 通常由兩個核心組件構成:檢索模塊和生成模塊。
檢索模塊(Retriever)
- 負責從外部知識來源中檢索與用戶查詢相關的文本。
- 通過嵌入模型(Embeddings)將文本轉換為高維向量,以捕捉文本的語義特徵。
- 檢索過程基於向量相似度(如餘弦相似度)來篩選最相關的文本片段。
生成模塊(Generator)
- 接收檢索模塊提供的相關文本片段作為上下文。
- 利用生成式模型(如 GPT、LLaMA)生成基於上下文的回答。
- 生成的結果不僅依賴查詢語句,還受到檢索到的外部文本片段的影響。
RAG 的技術流程
RAG流程圖
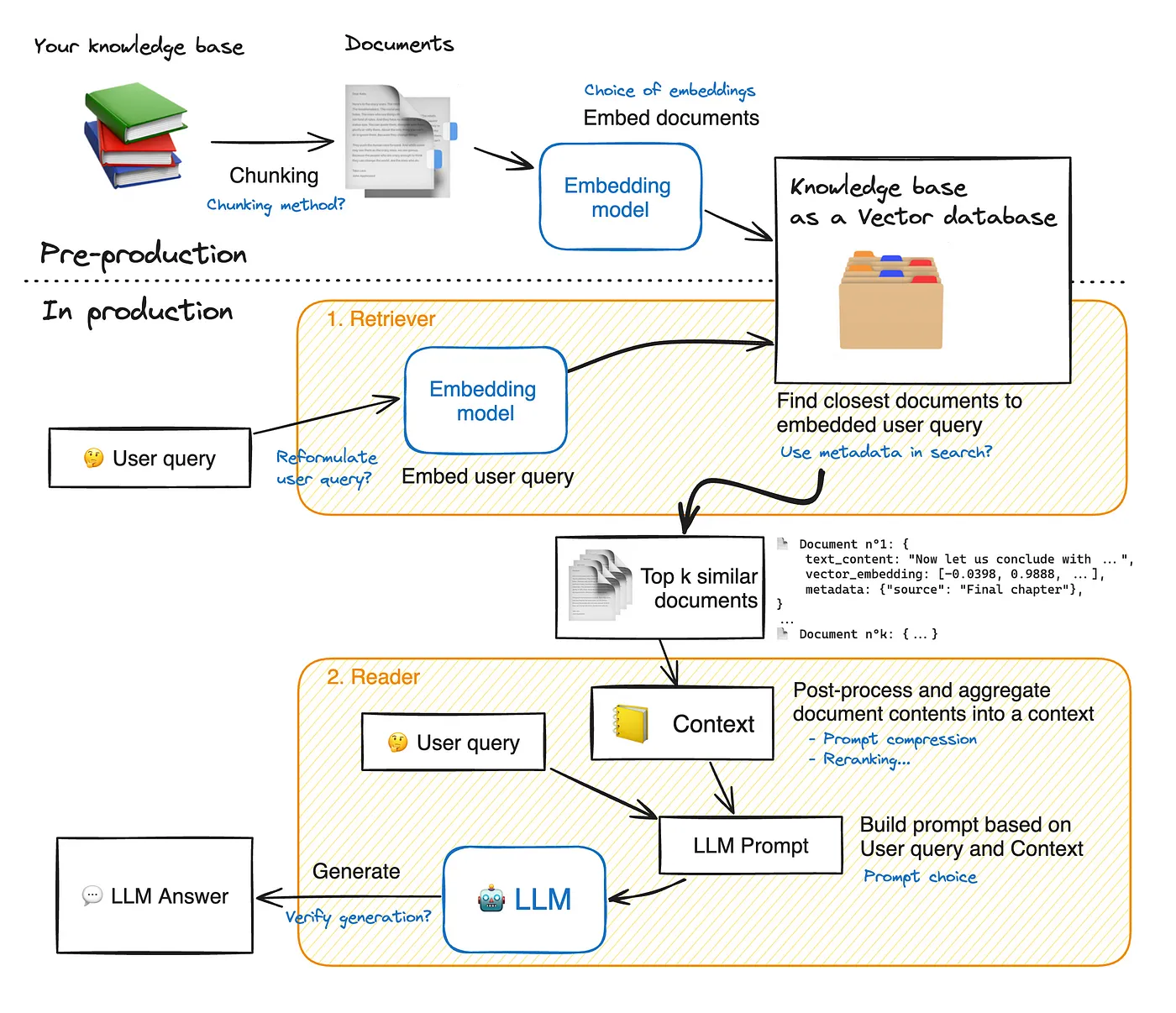
RAG運作圖參考自 https://huggingface.co/learn/cookbook/zh-CN/advanced_rag
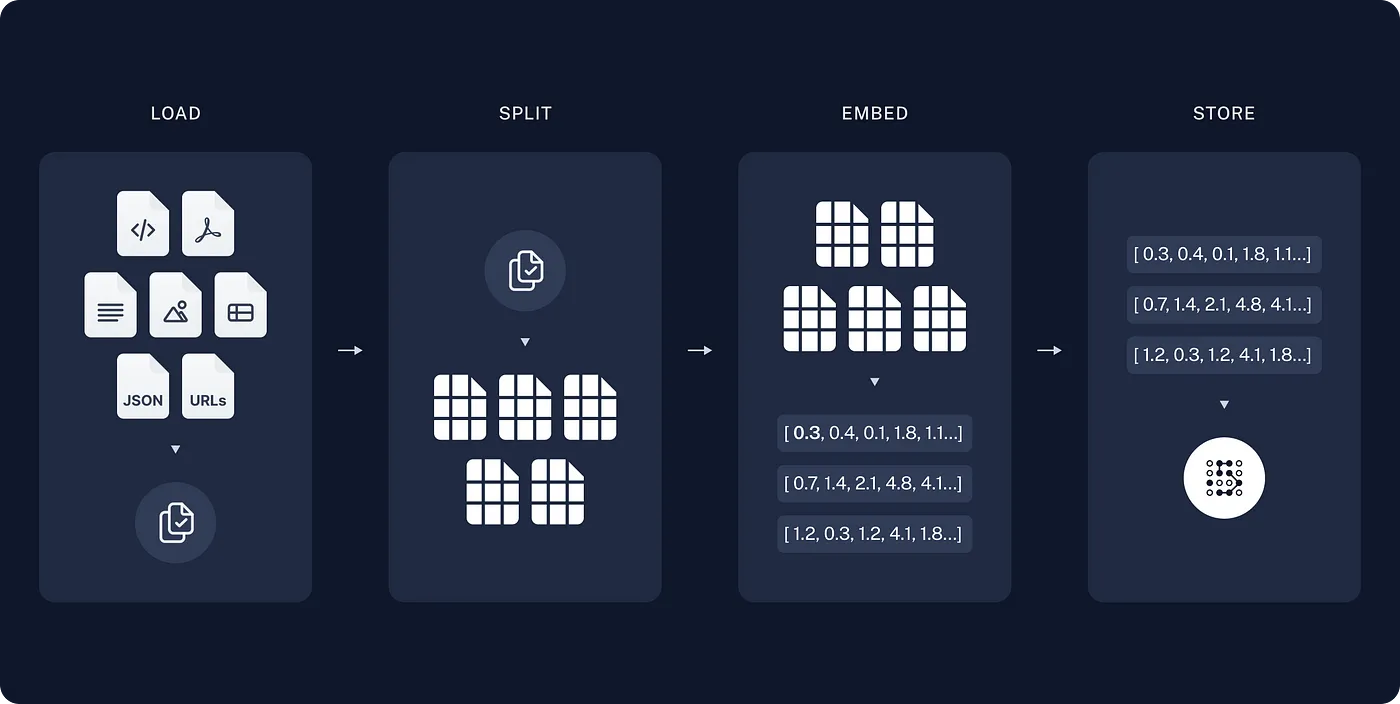
圖引用自 Langchain
數據準備
- 將外部知識庫(如 PDF、文檔)轉換為可檢索的格式。
- 使用嵌入模型生成每段文本的向量,並存入向量數據庫(如
Chroma或FAISS)。
查詢處理
- 將用戶查詢轉換為嵌入向量。
- 在向量數據庫中根據查詢向量檢索最相關的文本片段。
文本生成
- 將檢索到的文本與查詢一同傳入生成式模型。
- 根據檢索到的上下文生成針對性的回答。
RAG 的核心優勢
1. 準確性提升
- 結合外部知識,使生成模型在回答時能依據最新且相關的內容,而不僅依賴訓練期間的數據。
- 特別適用於需要高度專業知識的領域,如法律、醫療、技術文檔。
2. 動態性與靈活性
- 知識庫可以動態更新,無需對生成模型進行重新訓練。
- 支持處理多種格式的知識來源(PDF、Word、網頁)。
3. 節省計算資源
- 檢索模塊有效縮小了生成模型的處理範圍,減少不必要的推理工作。
RAG 與傳統生成模型的區別
| 特性 | 傳統生成模型 | RAG |
|---|---|---|
| 知識來源 | 模型內部預訓練知識 | 外部知識庫 |
| 回答更新 | 固定,無法動態更新 | 支持知識庫動態更新 |
| 準確性 | 依賴模型訓練數據 | 結合檢索,回答更精確 |
| 計算成本 | 處理整個上下文較昂貴 | 聚焦檢索結果,計算更高效 |
RAG 與相關技術的對比
RAG 作為一種結合檢索與生成的技術框架,與其他知識增強技術相比具有獨特的優勢。以下是一些關鍵技術的對比分析:
1. Fine-tuning vs. RAG
- Fine-tuning 是透過額外的數據對生成模型進行再訓練,以增強其在特定領域的能力。
- RAG 的優勢:
- 無需重新訓練模型,只需更新外部知識庫即可快速適應新知識。
- 適合動態性強的場景,例如新聞摘要或實時問答。
- 節省大量的計算資源,避免模型再訓練的高昂成本。
2. Prompt Engineering vs. RAG
- Prompt Engineering 是通過設計精巧的提示(Prompts)來引導模型生成更準確的回答。
- RAG 的優勢:
- 在提示中結合檢索到的上下文,提供更加具體和針對性的回應。
- Prompt Engineering 依賴於模型內部的知識,而 RAG 能補充外部最新資訊,克服模型知識過時的缺陷。
- 兩者結合:RAG 可以利用經過優化的提示工程進一步提升生成質量。
3. Retriever-Only System vs. RAG
- Retriever-Only System 只檢索外部知識庫並直接返回檢索結果,無生成過程。
- RAG 的優勢:
- 結合檢索內容進行定制化生成,針對複雜查詢提供更豐富的上下文回答。
- 解決檢索結果格式化和語意銜接的問題,例如將檢索到的多個片段整合為流暢的回答。
- 提升用戶體驗,減少用戶對檢索結果的二次理解成本。
RAG 的挑戰與改進方向
1. 檢索質量
- 問題:檢索模塊可能檢索到與查詢無關或不完全相關的文本片段。
- 解決方法:提高向量數據庫的檢索精度,如使用更好的嵌入模型。
2. 生成模型的依賴
- 問題:如果生成模型處理檢索文本的能力不足,回答可能仍不夠準確。
- 解決方法:選用性能更強的生成模型,或通過提示工程(Prompt Engineering)優化生成過程。
3. 文本分割策略
- 問題:如何設置適合的
chunk_size和chunk_overlap是一大挑戰。 - 解決方法:根據文檔特性調整文本分割參數,確保上下文連續性。
4. 計算資源需求
- 問題:大規模文檢索和生成可能需要較多的計算資源。
- 解決方法:優化檢索模塊效率,並選用適當的硬件資源。
RAG 的未來發展
1. 多模態支持
- 未來的 RAG 框架可能支持多模態數據(如圖片、視頻)的檢索和生成。
- 例如:結合圖像檢索和文本生成,用於醫學影像報告。
2. 增強型檢索技術
- 引入更加智能的檢索方法,如基於深度學習的增強檢索模塊,進一步提升相關性。
崴寶結語
RAG 是一種強大的技術框架,它成功將檢索和生成相結合,使得生成式 AI 能夠處理更加複雜的知識密集型任務。
喜歡 好崴寶 Weibert Weiberson 的文章嗎?在這裡留下你的評論!本留言區支援 Markdown 語法。
