

使用 Hugging Face 的 Transformers 庫來實現 BERT 模型的訓練微調fine-tuning:以進行垃圾郵件的辨識分類
日期:2024-05-14 23:56:11
使用 Hugging Face 的 Transformers 進行 BERT 模型微調以分類垃圾郵件
此文章也有發表在Medium上 >>
相關資料集
- SMSSpamCollection: 訓練會用到的 Dataset
- SMSSpamCollection_test: 測試會用到的 Dataset
相關檔案
- SMSSpamCollection_bert.py: 訓練檔案
- SMSSpamCollection_bert_predict.py: 預測檔案
GitHub Repository
- Bert HugginFace Train Predict SpamEmails
Contribute to weitsung50110/Bert HugginFace Train Predict SpamEmails development by creating an account on GitHub.
指令介紹
python SMSSpamCollection_bert.py # 訓練指令
python SMSSpamCollection_bert_predict.py # 預測指令
Docker
weitsung50110/bert_huggingface: 此為我安裝好的 Docker image 環境。
docker pull weitsung50110/bert_huggingface:1.0
訓練模型
資料準備
SMS Spam Collection Dataset 可以在 Kaggle 下載,我也有放在我的 GitHub repo 當中,SMSSpamCollection 歡迎大家取用。
模型準備
使用 BERT 模型的預訓練版本 “bert-base-uncased”,透過 BertForSequenceClassification 來建立文本分類模型。
初始化 tokenizer,將文本轉換成模型可接受的輸入格式。
| Model | #params | Language |
|---|---|---|
| bert-base-uncased | 110M | English |
| bert-large-uncased | 340M | English |
| bert-base-cased | 110M | English |
| bert-large-cased | 340M | English |
| bert-base-chinese | 110M | Chinese |
| bert-base-multilingual-cased | 110M | Multiple |
| bert-large-uncased-whole-word-masking | 340M | English |
| bert-large-cased-whole-word-masking | 340M | English |
根據 Hugging Face 官方文檔中,可以看到有非常多模型可以選擇,而本研究是使用 google-bert/bert-base-uncased。
Hugging Face BERT community: Hugging Face
- 初始化 tokenizer 和模型:使用 Hugging Face 的 Transformers 庫中的
BertTokenizer和BertForSequenceClassification類別,從預訓練的 BERT 模型中初始化 tokenizer 和分類模型。model_name指定了要使用的預訓練模型,這裡使用了bert-base-uncased,這是一個英文模型。
在後面預測的部分,tokenizer 有更詳細的教學。
準備資料集:從讀取的資料中取出文本和標籤,然後使用
train_test_split函式將資料集分成訓練集和驗證集,其中設置了驗證集佔總資料集的 20%。使用 tokenizer 轉換文字:將訓練集和驗證集的文本資料使用 tokenizer 轉換成模型可接受的輸入格式。這包括將文本轉換成 token IDs,並進行 padding 和截斷,確保每個輸入序列的長度相同,這裡設置了最大長度為 512。
建立自訂的 Dataset 類別:定義了一個自訂的 Dataset 類別,用來封裝資料集,使其可以被 PyTorch 的 DataLoader 使用。該類別接受 tokenized 的資料和對應的標籤,並在
__getitem__方法中將其轉換成 PyTorch 張量格式。建立訓練集和驗證集的 Dataset 物件:將 tokenized 的訓練集和驗證集資料以及對應的標籤傳入自訂的 Dataset 類別,建立訓練集和驗證集的 Dataset 物件。
這樣做的目的是為了準備好訓練所需的資料格式,使其可以被 PyTorch 模型接受並用於訓練。
使用 tokenizer 轉換文字
定義了一個自訂的 Dataset 類別,用來建立訓練集和驗證集的 Dataset。
# 初始化 tokenizer
tokenizer = BertTokenizer.from_pretrained(model_name)
# 初始化模型
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
# 將資料集分成訓練集和驗證集
X = list(df['message'])
y = list(df['label'])
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
# 使用 tokenizer 將文字轉換為模型可接受的輸入格式
X_train_tokenized = tokenizer(X_train, padding=True, truncation=True, max_length=512)
X_val_tokenized = tokenizer(X_val, padding=True, truncation=True, max_length=512)
建立自訂的 Dataset 類別
class Dataset(torch.utils.data.Dataset):
def __init__(self, encodings, labels=None):
self.encodings = encodings
self.labels = labels
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
if self.labels:
item["labels"] = torch.tensor(self.labels[idx])
return item
def __len__(self):
return len(self.encodings["input_ids"])
建立訓練集和驗證集的 Dataset 物件:
train_dataset = Dataset(X_train_tokenized, y_train)
val_dataset = Dataset(X_val_tokenized, y_val)
訓練模型
定義了計算評估指標的函式,包括準確率(accuracy)、召回率(recall)、精確率(precision)、F1 分數(F1 score)。
def compute_metrics(p):
pred, labels = p
pred = np.argmax(pred, axis=1)
accuracy = accuracy_score(y_true=labels, y_pred=pred)
recall = recall_score(y_true=labels, y_pred=pred)
precision = precision_score(y_true=labels, y_pred=pred)
f1 = f1_score(y_true=labels, y_pred=pred)
return {"accuracy": accuracy, "precision": precision, "recall": recall, "f1": f1}
初始化了 Trainer,設定了訓練相關的參數,包括訓練集、驗證集、計算評估指標的函式等。
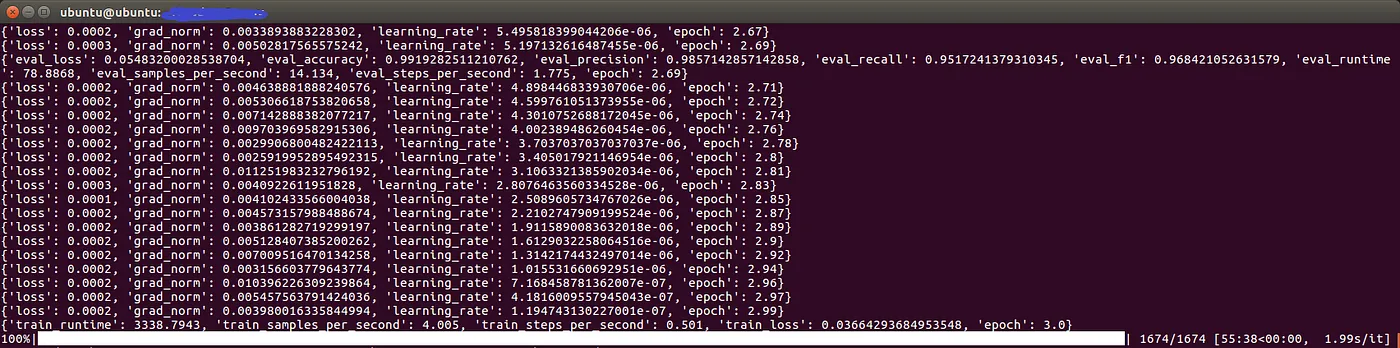
使用 trainer.train() 開始訓練模型,同時設置了提前停止訓練的機制,以防止過度擬合。
訓練參數說明
output_dir: 指定訓練過程中模型和日誌等輸出的目錄。
evaluation_strategy: 指定評估策略,這裡設置為 “steps”,表示基於步驟數進行評估。
eval_steps: 指定在訓練過程中每隔多少步進行一次評估。
per_device_train_batch_size: 每個訓練裝置(device)的批次大小。
per_device_eval_batch_size: 每個評估裝置的批次大小。
num_train_epochs: 訓練的總時代數(epochs)。
seed: 隨機種子,用於重現性。
load_best_model_at_end: 是否在訓練結束時載入最佳模型。
logging_steps: 每隔多少步輸出一次訓練日誌。
report_to: 指定將訓練進度報告到哪個工具,這裡設置為 “tensorboard”,表示將訓練進度報告到 TensorBoard。
args = TrainingArguments( output_dir="output", evaluation_strategy="steps", eval_steps=500, per_device_train_batch_size=8, per_device_eval_batch_size=8, num_train_epochs=3, seed=0, load_best_model_at_end=True, logging_steps=10, report_to="tensorboard", )
seed 參數是用於設置隨機種子的,它的作用是確保在訓練過程中的隨機操作(例如參數初始化、數據順序洗牌等)是可重現的。通常情況下,當我們希望每次運行訓練過程時得到相同的結果時,就會設置隨機種子。這對於實驗的可重現性和結果的一致性非常重要。
load_best_model_at_end 參數用於控制是否在訓練結束時載入最佳的模型。在訓練過程中,模型的性能可能會隨著時間逐漸提升或者下降,因此通常會在每個評估步驟或者一定間隔之後進行模型性能的評估,並保存當前最佳的模型。當訓練結束時,這個參數可以確保載入最佳的模型,而不是最後一個模型,這樣可以確保我們得到的是在驗證集上性能最好的模型。
預測模型
文本被 tokenized 後會變成什麼模樣?
X_test_tokenized = tokenizer(X_test, padding=True, truncation=True, max_length=512)
print(X_test_tokenized)
X_test_tokenized 裡面包含 Tokenization 的結果,每個樣本都包含了三個部分:input_ids、token_type_ids 和 attention_mask。
{'input_ids': [[101, 2323, 1045, 3288, 1037, 5835, 1997, 4511, 2000, 2562, 2149, 21474, 1029, 2074, 12489, 999, 1045, 1521, 2222, 3288, 2028, 7539, 1012, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[101, 2131, 1996, 6745, 2718, 3614, 5524, 2005, 2489, 999, 11562, 2023, 4957, 1024, 8299, 1013, 1013, 1056, 5244, 1012, 2898, 3669, 3726, 1012, 4012, 1013, 5950, 1012, 1059, 19968, 1029, 8909, 1027, 26667, 24087, 2549, 4215, 2692, 27717, 19841, 24087, 2581, 22907, 14526, 1004, 2034, 1027, 2995, 1067, 1039, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
1. input_ids
這是每個文本樣本轉換後的 token 序列。每個 token 都對應到 BERT 模型的詞彙表中的一個索引。在這個例子中,每個樣本都包含了一個長度為 50 的 token 序列。如果某個樣本的 token 數量不足 50,則會使用 0 進行填充,直到達到指定的序列長度。
- 101 代表
[CLS]符號。 表示句子的開始。 - 102 代表
[SEP]符號。 表示句子的結束或分隔不同的句子。
2. token_type_ids
這個部分是用來區分不同句子的。在這裡,所有的 token 都屬於同一個句子,因此對應的值都是 0。在處理文本對任務時,將會有兩個句子,並使用 0 和 1 來區分它們。
3. attention_mask
這個部分用來指示哪些 token 是模型在處理時應該關注的。在這裡,所有的 token 都是被處理的,因此對應的值都是 1。在填充的部分,對應的值則是 0,用於告訴模型這些部分是填充的,不應該參與計算。
這些 tokenization 結果是 BERT 模型在處理文本數據時所需的輸入格式,其中包括了文本的 token 序列、句子區分和注意力遮罩等信息。
預測結果
# Make prediction
raw_pred, _, _ = test_trainer.predict(test_dataset)
# Preprocess raw predictions
y_pred = np.argmax(raw_pred, axis=1)
raw_pred 為包含 9 個元素的一維數組。
[[ 4.478097 -4.762506 ]
[-3.7398722 3.903498 ]
[-3.7016623 3.8625014]
[-3.7578042 3.9365413]
[-3.6734304 3.8043854]
[ 4.5997095 -4.8369007]
[-3.3514545 3.4255216]
[-3.7296603 3.8799422]
[ 3.270107 -3.534067 ]]
np.argmax 函式返回一個包含 9 個元素的一維數組,其中每個元素是對應行的預測結果(0 或 1)。
如果第一個數值較大,則對應位置的元素為 0;如果第二個數值較大,則對應位置的元素為 1。

最後預測出來的答案如下:
[0, 1, 1, 1, 1, 0, 1, 1, 0] # 預測答案
預測正確!!
基本上只要在內容有寫上 “free”、”click link” 之類的字樣,就很容易判斷為垃圾郵件。
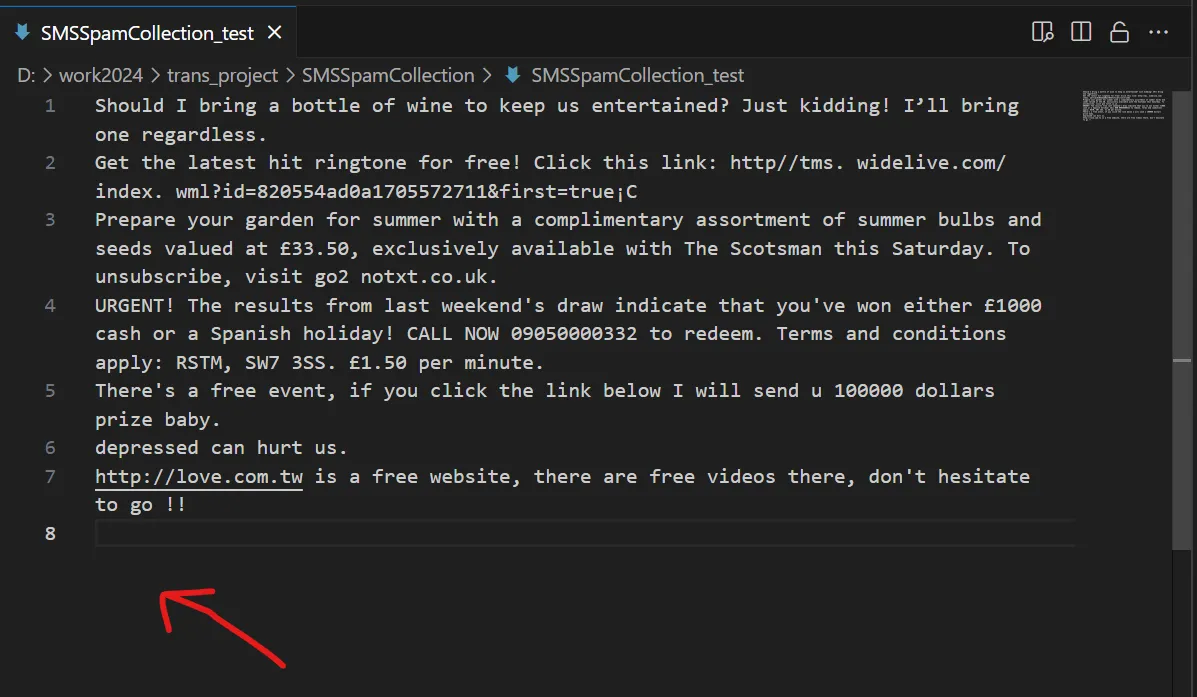
測試 Dataset
在 SMSSpamCollection_test 當中,
- Bert HugginFace Train Predict SpamEmails/SMSSpamCollection test
Contribute to weitsung50110/Bert HugginFace Train Predict SpamEmails
大家可以發揮創意,在測試 Dataset 加入自己的郵件語句,實測模型能否辨認出來。
添加方式
- 可以直接加在資料集的最下面即可。
- 把舊的句子刪掉,把你想預測的寫在第一列,這樣結果就會只有一個輸出。
喜歡 Weiberson 的文章嗎?在這裡留下你的評論!本留言區支援 Markdown 語法。



