

LangChain結合大型語言模型(LLM)讀取網頁,分析網頁並產生重點摘要,進行有記憶性的對話
日期:2024-06-07 02:19:11
結合LangChain與大型語言模型(LLM),即時讀取和分析網頁內容,生成精華摘要,並實現具有記憶性的智能對話。
藉由有記憶性的聊天機器人的實作,我們可以向LLM詢問網頁相關的問題,LLM會分析網頁內容,產生重點摘要。此文還會介紹Document loaders和官方API的應用。
需要文件下載
- Github Repository — weitsung50110/Huggingface Langchain kit
本文是使用到裡面的langchain web Conversation Retrieval.py檔案。
因為此教學有使用到變數MessagesPlaceholder和提示模板,來達成基於對話歷史生成相關的搜索查詢,因此建議新手可以讀完這篇再繼續!!
此文章也有發表在Medium上 >>
document_loaders介紹
官方API文檔
document_loaders官方說有支援 CSV, HTML, JSON, Markdown, PDF 等等,而Langchain光是PDF就有超多不同種的loaders,請參考官方API文檔,在langchain_community.document loaders裡面。
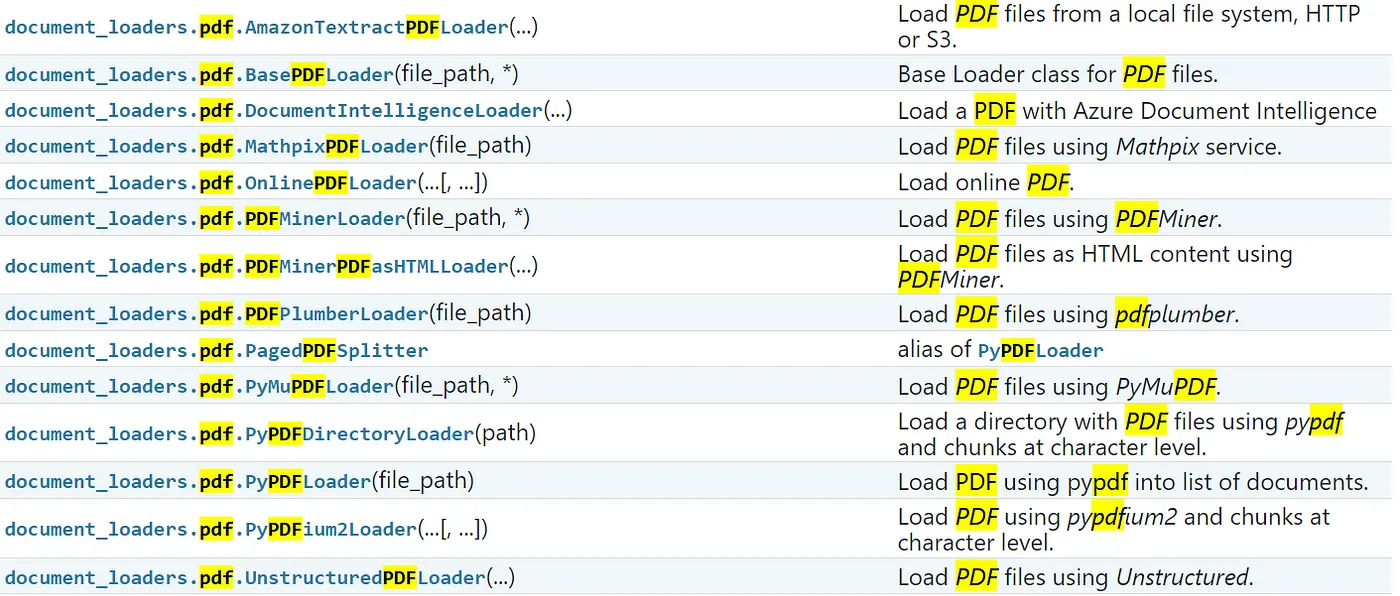
| Loader | Description |
|---|---|
| AmazonTextractPDFLoader(…) | Load PDF files from a local file system, HTTP, or S3. |
| BasePDFLoader(file_path, *) | Base Loader class for PDF files. |
| DocumentIntelligenceLoader(…) | Load a PDF with Azure Document Intelligence. |
| MathpixPDFLoader(file_path) | Load PDF files using Mathpix service. |
| OnlinePDFLoader(…[, …]) | Load online PDF. |
| PDFMinerLoader(file_path, *) | Load PDF files using PDFMiner. |
| PDFMinerPDFasHTMLLoader(…) | Load PDF files as HTML content using PDFMiner. |
| PDFPlumberLoader(file_path) | Load PDF files using pdfplumber. |
| PagedPDFSplitter | Alias of PyPDFLoader. |
| PyMuPDFLoader(file_path, *) | Load PDF files using PyMuPDF. |
| PyPDFDirectoryLoader(path) | Load a directory with PDF files using pypdf and chunks at character level. |
| PyPDFLoader(file_path) | Load PDF using pypdf into a list of documents. |
| PyPDFium2Loader(…[, …]) | Load PDF using pypdfium2 and chunks at character level. |
| UnstructuredPDFLoader(…) | Load PDF files using Unstructured. |
官網文檔
而比較常出現的範例,可以參考官網文檔。
像是如果你需要CSVLoader,就可以照著官方給的範例修改。
from langchain_community.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv')
data = loader.load()
本文這次會使用WebBaseLoader來加載web網頁,可以看到右邊的介紹說這個套件是使用BeautifulSoup來實作的。
實作教學
1.加載和處理文檔
我們將使用 WebBaseLoader 從指定的網址加載文檔
from langchain_community.document_loaders import WebBaseLoader
# 使用 WebBaseLoader 從指定網址加載文檔
loader = WebBaseLoader("https://www.ollama.com/")
docs = loader.load()
本文使用https://www.ollama.com 來實作,因為這個網頁東西比較少,所以跑比較快。
2.TextSplitter切割成chunk
使用 RecursiveCharacterTextSplitter 將文檔分割成較小的塊。
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 使用 RecursiveCharacterTextSplitter 將文檔分割成較小的塊
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
documents = text_splitter.split_documents(docs)
3.初始化語言模型和嵌入模型
初始化 Ollama 語言模型和嵌入模型,並使用 FAISS 創建向量數據庫來存儲分割後的文檔。
from langchain_community.llms import Ollama
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS
# 初始化 Ollama 語言模型
llm = Ollama(model='llama3')
# 初始化 Ollama 嵌入模型
embeddings = OllamaEmbeddings()
# 使用 FAISS 創建向量數據庫並加載分割後的文檔
vector = FAISS.from_documents(documents, embeddings)
retriever = vector.as_retriever()
4.創建提示模板
我們需要兩個提示模板:一個用於生成搜索查詢,另一個用於基於檢索到的文檔生成答案。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts import MessagesPlaceholder
# 創建用於生成搜索查詢的提示模板
prompt_search_query = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up in order to get information relevant to the conversation")
])
# 創建用於獲取答案的提示模板
prompt_get_answer = ChatPromptTemplate.from_messages([
('system', 'Answer the user\'s questions based on the below context:\n\n{context}'),
MessagesPlaceholder(variable_name="chat_history"),
('user', '{input}'),
])
5.創建檢索鏈和文檔鏈
我們使用上述提示模板創建帶有歷史上下文的檢索器和文檔鏈,然後結合這兩者來創建檢索鏈。
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
# 創建帶有歷史上下文的檢索器
retriever_chain = create_history_aware_retriever(llm, retriever, prompt_search_query)
# 創建文檔鏈以生成答案
document_chain = create_stuff_documents_chain(llm, prompt_get_answer)
# 結合檢索器和文檔鏈,創建檢索鏈
retrieval_chain_combine = create_retrieval_chain(retriever_chain, document_chain)
6.構建問答系統
最後,我們構建一個循環來接收用戶輸入,調用檢索鏈生成回答,並print結果。
from langchain_core.messages import HumanMessage, AIMessage
# 初始化聊天歷史記錄
chat_history = []
input_text = input('>>> ')
while input_text.lower() != 'bye':
if input_text:
# 調用檢索鏈並獲取回答
response = retrieval_chain_combine.invoke({
'input': input_text,
'chat_history': chat_history,
})
# 打印回答
print(response['answer'])
# 將用戶輸入和 AI 回答添加到聊天歷史中
chat_history.append(HumanMessage(content=input_text))
chat_history.append(AIMessage(content=response['answer']))
input_text = input('>>> ')
成果展示 — 第一次和LLM對話
我們第一次問llama3說”Hi, my name is weiberson, could you tell me what is this about?”,
可以看到LLM說”Nice to meet you, Weiberson!”後開始介紹Ollama是什麼樣的網站~
root@c8c21d9dfc73:/app# python3 langchain_web_Conversation_Retrieval.py
>>> Hi, my name is weiberson, could you tell me what is this about?
Nice to meet you, Weiberson!
This appears to be the website of Ollama, a platform that allows users to run and customize large language models. The main features highlighted are the ability to download and use various models such as Llama 3, Phi 3, Mistral, Gemma, and more, as well as the option to create your own custom models.
The website seems to be focused on providing a flexible and user-friendly experience for those who want to work with language models. There are sections for searching and exploring models, downloading them, and even signing in to access additional features.
What specific questions do you have about Ollama or its services? I'm here to hel
容易搞不懂的地方之解析😝1
若我們把response給print出來,可以發現是長如下:
input: 你輸入的文字。chat_history: 因為是第一次輸入所以是空的。context[Document{page_content}]: 是 BeautifulSoup 爬下來的網頁內容。context[Document{metadata}]: 中的source, title, description, language,都是對應https://www.ollama.com/ 的html,可以去查看網頁原始碼進行比對。context[Document{metadata}]中的answer: 是 LLM 回答我們的答案。{'input': 'Hi, my name is weiberson, could you tell me what is this about?', 'chat_history': [], 'context': [Document(page_content='Ollama\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nModels\nSearch\nDiscord\nGitHub\nDownload\nSign in\n\n\n\n\n\nBlog\n\n Discord\n \n\n GitHub\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\nModels\nSign in\n\n Download\n \n\n\n\n\n\n\n\n\n\n\n Get up and running with large language models.\n \n\n Run Llama 3, Phi 3, Mistral, Gemma, and other models. Customize and create your own.\n \n\n\n\n Download\xa0\xa0↓\n \n\n Available for macOS, Linux, and Windows (preview)\n \n\n\n\n Explore models\xa0\xa0→\n \n\n Available for macOS, Linux, and Windows (preview)\n \n\n\n\n\n\n\n© 2024 Ollama\n\nBlog\nDocs\nGitHub\nDiscord\nX (Twitter)\nMeetups\n\n\n\n\n\n\nBlog\nDocs\nGitHub\n\n\nDiscord\nX (Twitter)\nMeetups\n\n\n © 2024 Ollama', metadata={ 'source': 'https://www.ollama.com/', 'title': 'Ollama', 'description': 'Get up and running with large language models.', 'language': 'No language found.'})], 'answer': "Nice to meet you, Weiberson! This appears to be the website of Ollama, a platform that allows users to run and customize large language models. The main features highlighted are the ability to download and use various models such as Llama 3, Phi 3, Mistral, Gemma, and more, as well as the option to create your own custom models.\n\nThe website seems to be focused on providing a flexible and user-friendly experience for those who want to work with language models. There are sections for searching and exploring models, downloading them, and even signing in to access additional features.\n\nWhat specific questions do you have about Ollama or its services? I'm here to help!"}
成果展示 — Chat History有記憶的對話機器人
我們第二次問llama3說”could you summarize the key points for me?”,
可以看到LLM已經記得我的名字叫做Weiberson,並幫我總結了Ollama網站的功能。
>>> could you summarize the key points for me?
Weiberson!
Here's a summary of the key points:
1. **Ollama** is a platform that allows users to run and customize large language models.
2. The platform offers various pre-trained models, including Llama 3, Phi 3, Mistral, Gemma, and more.
3. Users can **download** these models for use on their devices (macOS, Linux, and Windows).
4. The platform also allows users to create their own custom models.
5. There are sections for:
* **Searching** and exploring available models
* **Downloading** models
* **Signing in** to access additional features
Let me know if you have any further questions or if there's anything else I can help with!
容易搞不懂的地方之解析😝2
若我們把response給print出來,可以發現是長如下:
可以看到變數chat_history當中,有之前和LLM聊天的紀錄,並分為HumanMessage和AIMessage個別儲存。
{'input': 'could you summarize the key points for me?',
'chat_history': [HumanMessage(content='Hi, my name is weiberson, could you tell me what is this about?'),
AIMessage(content="Nice to meet you, Weiberson! This appears to be the website of Ollama, a platform that allows users to run and customize large language models. The main features highlighted are the ability to download and use various models such as Llama 3, Phi 3, Mistral, Gemma, and more, as well as the option to create your own custom models.\n\nThe website seems to be focused on providing a flexible and user-friendly experience for those who want to work with language models. There are sections for searching and exploring models, downloading them, and even signing in to access additional features.\n\nWhat specific questions do you have about Ollama or its services? I'm here to help!")],
'context': [Document(page_content='Ollama\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nModels\nSearch\nDiscord\nGitHub\nDownload\nSign in\n\n\n\n\n\nBlog\n\n Discord\n \n\n GitHub\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\nModels\nSign in\n\n Download\n \n\n\n\n\n\n\n\n\n\n\n Get up and running with large language models.\n \n\n Run Llama 3, Phi 3, Mistral, Gemma, and other models. Customize and create your own.\n \n\n\n\n Download\xa0\xa0↓\n \n\n Available for macOS, Linux, and Windows (preview)\n \n\n\n\n Explore models\xa0\xa0→\n \n\n Available for macOS, Linux, and Windows (preview)\n \n\n\n\n\n\n\n© 2024 Ollama\n\nBlog\nDocs\nGitHub\nDiscord\nX (Twitter)\nMeetups\n\n\n\n\n\n\nBlog\nDocs\nGitHub\n\n\nDiscord\nX (Twitter)\nMeetups\n\n\n © 2024 Ollama',
metadata={
'source': 'https://www.ollama.com/',
'title': 'Ollama',
'description': 'Get up and running with large language models.',
'language': 'No language found.'})],
'answer': "Weiberson!\n\nHere's a summary of the key points:\n\n1. **Ollama** is a platform that allows users to run and customize large language models.\n2. The platform offers various pre-trained models, including Llama 3, Phi 3, Mistral, Gemma, and more.\n3. Users can **download** these models for use on their devices (macOS, Linux, and Windows).\n4. The platform also allows users to create their own custom models.\n5. There are sections for:\n\t* **Searching** and exploring available models\n\t* **Downloading** models\n\t* **Signing in** to access additional features\n\nLet me know if you have any further questions or if there's anything else I can help with!"}
和LLM的第三次對話
再次詢問Llama3我的名字叫什麼?
可以看到Llama3還清楚記得我叫做Weiberson😚
>>> do you remember what my name is?
Weiberson! Yes, I remember that your name is Weiberson.
How can I assist you further?
在第三次對話中,我們把response給print出來,請大家觀察chat_history裡面包含了前兩次對話的HumanMessage和AIMessage。
{'input': 'do you remember what my name is?',
'chat_history': [
HumanMessage(content='Hi, my name is weiberson, could you tell me what is this about?'),
AIMessage(content="Nice to meet you, Weiberson! This appears to be the website of Ollama, a platform that allows users to run and customize large language models. The main features highlighted are the ability to download and use various models such as Llama 3, Phi 3, Mistral, Gemma, and more, as well as the option to create your own custom models.\n\nThe website seems to be focused on providing a flexible and user-friendly experience for those who want to work with language models. There are sections for searching and exploring models, downloading them, and even signing in to access additional features.\n\nWhat specific questions do you have about Ollama or its services? I'm here to help!"),
HumanMessage(content='could you summarize the key points for me?'),
AIMessage(content="Weiberson!\n\nHere's a summary of the key points:\n\n1. **Ollama** is a platform that allows users to run and customize large language models.\n2. The platform offers various pre-trained models, including Llama 3, Phi 3, Mistral, Gemma, and more.\n3. Users can **download** these models for use on their devices (macOS, Linux, and Windows).\n4. The platform also allows users to create their own custom models.\n5. There are sections for:\n\t* **Searching** and exploring available models\n\t* **Downloading** models\n\t* **Signing in** to access additional features\n\nLet me know if you have any further questions or if there's anything else I can help with!")],
'context': [Document(page_content='Ollama\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nModels\nSearch\nDiscord\nGitHub\nDownload\nSign in\n\n\n\n\n\nBlog\n\n Discord\n \n\n GitHub\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\nModels\nSign in\n\n Download\n \n\n\n\n\n\n\n\n\n\n\n Get up and running with large language models.\n \n\n Run Llama 3, Phi 3, Mistral, Gemma, and other models. Customize and create your own.\n \n\n\n\n Download\xa0\xa0↓\n \n\n Available for macOS, Linux, and Windows (preview)\n \n\n\n\n Explore models\xa0\xa0→\n \n\n Available for macOS, Linux, and Windows (preview)\n \n\n\n\n\n\n\n© 2024 Ollama\n\nBlog\nDocs\nGitHub\nDiscord\nX (Twitter)\nMeetups\n\n\n\n\n\n\nBlog\nDocs\nGitHub\n\n\nDiscord\nX (Twitter)\nMeetups\n\n\n © 2024 Ollama',
metadata={
'source': 'https://www.ollama.com/',
'title': 'Ollama',
'description': 'Get up and running with large language models.',
'language': 'No language found.'})],
'answer': 'Weiberson! Yes, I remember that your name is Weiberson. How can I assist you further?'}
References
https://myapollo.com.tw/blog/langchain-document-loaders-text-splitters/
https://www.linkedin.com/pulse/beginners-guide-conversational-retrieval-chain-using-langchain-pxhjc
https://api.python.langchain.com/en/latest/community_api_reference.html#id21
https://python.langchain.com/v0.1/docs/modules/data_connection/document_loaders/
喜歡 Weiberson 的文章嗎?在這裡留下你的評論!本留言區支援 Markdown 語法。



