

LangChain RAG實作教學,結合Llama3讓LLM可以讀取PDF和DOC文件,並產生回應
日期:2024-05-28
使用Ollama來引入最新的Llama3大語言模型,來實作LangChain RAG教學。
LangChain Retrieval Augmented
因為RAG不用重新訓練模型,而且Dataset是你自己準備的,餵食LLM即時又準確的Dataset,可以解決LLM資料有時間限制的問題,因此近期在NLP領域非常受歡迎。
需要知識
需要文件下載
- Github Repository — weitsung50110/Huggingface Langchain kit
本文是使用到裡面的langchain_rag_doc.py和langchain_rag_pdf.py檔案。
關於Hugging Face的介紹可以參考這篇 - 使用 Hugging Face 的Pipeline來實現本地端文字轉圖片(Text-to-Image),進行圖片生成
此文章也有發表在Medium上 >>
RAG流程圖
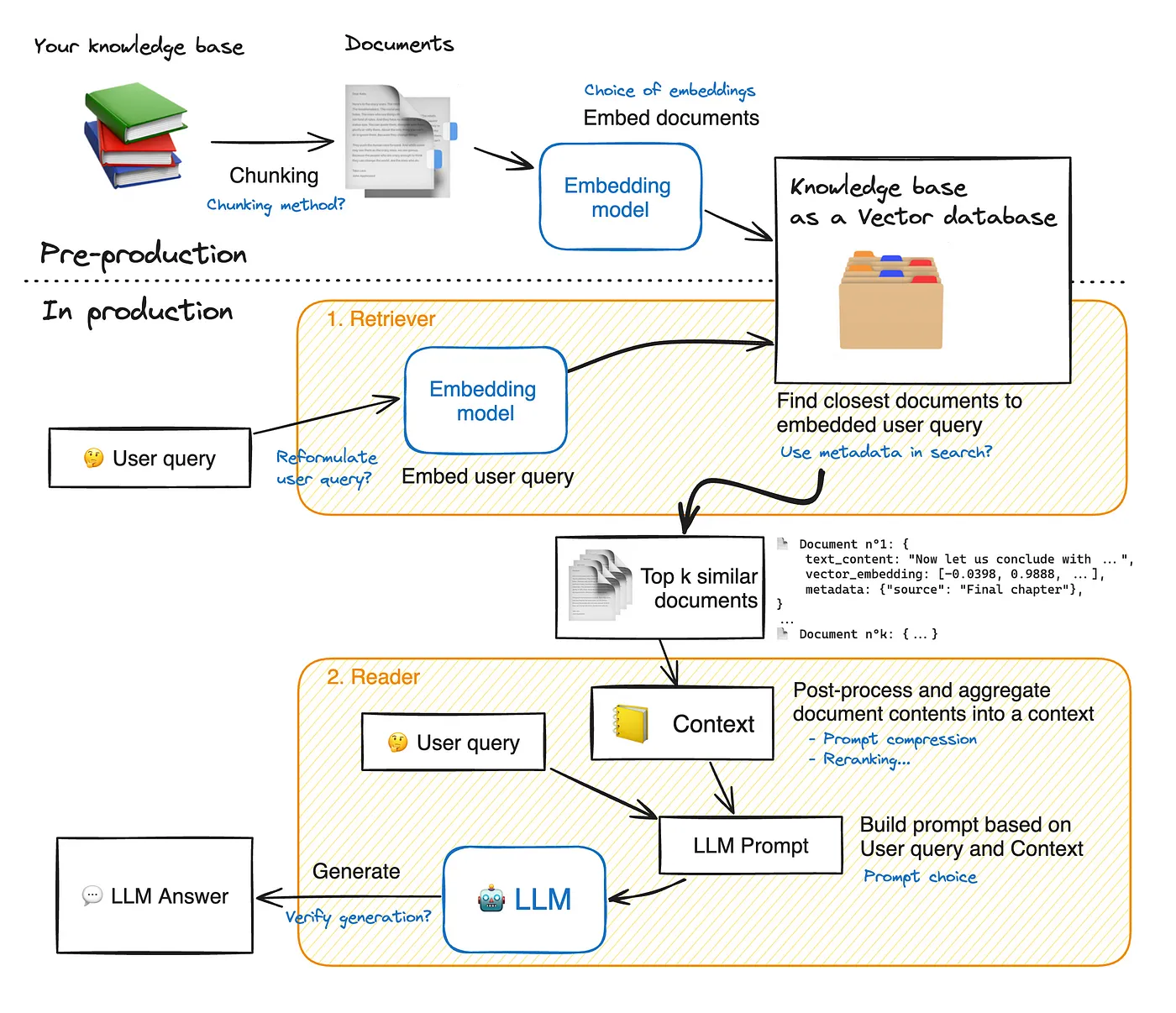
RAG運作圖參考自 https://huggingface.co/learn/cookbook/zh-CN/advanced_rag
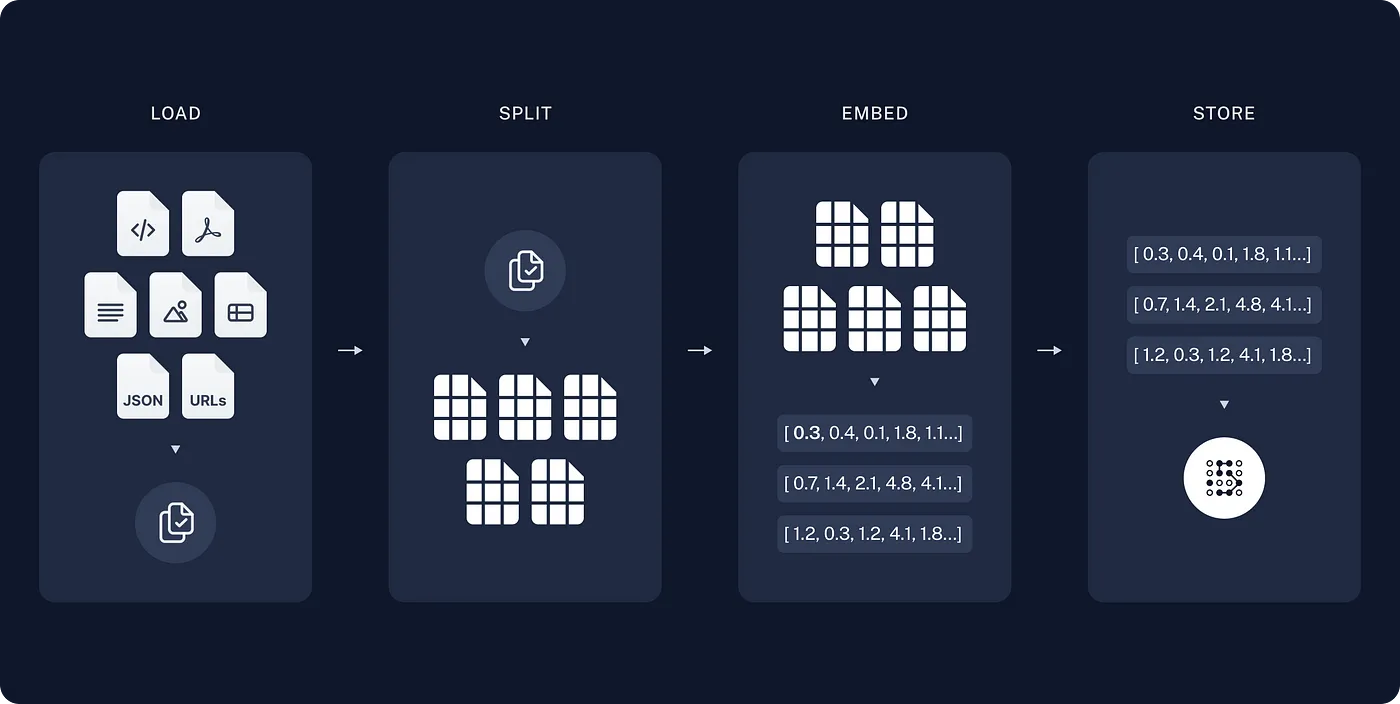
圖引用自 Langchain
實作教學
langchain_rag_doc.py >> 這個_doc代表是匯入文件檔案doc
你會需要import以下套件
from langchain.chains.combine_documents import create_stuff_documents_chain from langchain.chains import create_retrieval_chain from langchain_core.prompts import ChatPromptTemplate from langchain_community.llms import Ollama from langchain_community.embeddings import OllamaEmbeddings from langchain_community.vectorstores import FAISS from langchain_core.documents import Document from langchain_community.document_loaders import PyPDFLoader from langchain.text_splitter import CharacterTextSplitter
本文會匯入Doc文件和PDF來示範,分別為以下兩行
from langchain_core.documents import Document
from langchain_community.document_loaders import PyPDFLoader
建立模型和文件
# 初始化Ollama模型 llm = Ollama(model='llama3') # 建立文件列表,每個文件包含一段文字內容 docs = [ Document(page_content='曼德珍珠奶茶草:這種植物具有強大的魔法屬性,常用於恢復被石化的受害者。'), Document(page_content='山羊可愛蓮花石 :是一種從山羊胃中取出的石頭,可以解百毒。在緊急情況下,它被認為是最有效的解毒劑。'), Document(page_content='日本小可愛佐籐鱗片:這些鱗片具有強大的治愈能力,常用於製作治療藥水,特別是用於治療深層傷口。'), ]
文件中的內容建議自創,因為你若寫普世通俗的內容,那麼Llama3本來就已經知道了,因此效果會沒那麼顯著~
設定文本分割器
# 設定文本分割器,chunk_size是分割的大小,chunk_overlap是重疊的部分 text_splitter = CharacterTextSplitter(chunk_size=20, chunk_overlap=5) documents = text_splitter.split_documents(docs) # 將文件分割成更小的部分
chunk_size (塊大小)
定義: 每個分割塊的大小,以字符數量為單位。
作用: 決定每個文本塊包含多少字符。
chunk_overlap (塊重疊)
定義: 相鄰文本塊之間重疊的字符數量。
作用: 確保每個分割後的文本塊之間有一些重疊部分,以保證連貫性和上下文不丟失。
為什麼需要 chunk_overlap?
在自然語言處理和其他文本分析任務中,連貫性和上下文信息非常重要。
通過設置塊重疊部分,我們可以確保每個分割後的文本塊仍然包含足夠的上下文信息,避免因切割造成的信息丟失或語義斷裂。
文本分割器的選擇非常多,詳情可以參考官方api文獻和官方Text Splitters說明,不過多數情況用 Recursive 即可,關於RecursiveCharacterTextSplitter的使用可以參考Recursively split by character文檔。
建置embeddings和向量資料庫
# 初始化嵌入模型 embeddings = OllamaEmbeddings() # 使用FAISS建立向量資料庫 vectordb = FAISS.from_documents(docs, embeddings) # 將向量資料庫設為檢索器 retriever = vectordb.as_retriever()設定提示模板
# 設定提示模板,將系統和使用者的提示組合 prompt = ChatPromptTemplate.from_messages([ ('system', 'Answer the user\'s questions in Chinese, based on the context provided below:\n\n{context}'), ('user', 'Question: {input}'), ])llm和提示模板結合
# 創建文件鏈,將llm和提示模板結合 document_chain = create_stuff_documents_chain(llm, prompt) # 創建檢索鏈,將檢索器和文件鏈結合 retrieval_chain = create_retrieval_chain(retriever, document_chain)從用戶輸入中獲取問題,並用retrieval_chain來回答
context = [] input_text = input('>>> ') while input_text.lower() != 'bye': response = retrieval_chain.invoke({ 'input': input_text, 'context': context }) print(response['answer']) context = response['context'] input_text = input('>>> ')
retrieval_chain.invoke 是執行這條chain的代碼,以前的教學或許會看到.run,但最新版本的LangChain會慢慢用.invoke當主流。
RUN程式,開始問Llama3問題吧:>
root@4be643ba6a94:/app# python3 langchain_rag_doc.py
>>> 請告訴我珍珠奶茶是?
🤔
曼德珍珠奶茶草:這種植物具有強大的魔法屬性,常用於恢復被石化的受害者。
‘context’: context
如果把context註解掉的話,程式也可以RUN,但留著 ‘context’: context看起來會比較直觀。
# context = []
input_text = input('>>> ')
while input_text.lower() != 'bye':
response = retrieval_chain.invoke({
'input': input_text,
# 'context': context
})
print(response['answer'])
# context = response['context']
input_text = input('>>> ')
若我們把程式碼改成如下,把response給print出來~
while input_text.lower() != 'bye':
response = retrieval_chain.invoke({
'input': input_text,
'context': context
})
print(response['answer'])
context = response['context']
print("-------------------")
print(response)
input_text = input('>>> ')
可以看到結果如下,裡面會分別有response['input']、response['context']、response['answer']
root@4be643ba6a94:/app# python3 langchain_rag_doc.py
>>> 有哪些工具可以用?
🐐💧️
有以下幾種工具可以使用:
* 山羊可愛蓮花石:可以解百毒,對於急性中毒非常有效。
* 日本小可愛佐籐鱗片:具有強大的治愈能力,可以用於製作治療藥水,特別是深層傷口的治療。
* 曼德珍珠奶茶草:具有強大的魔法屬性,常用於恢復被石化的受害者。
這些工具都可以幫助你解決問題! 💪️
-------------------
{'input': '有哪些工具可以用?',
'context': [Document(page_content='山羊可愛蓮花石 :是一種從山羊胃中取出的石頭,可以解百毒。在緊急情況下,它被認為是最有效的解毒劑。'),
Document(page_content='日本小可愛佐籐鱗片:這些鱗片具有強大的治愈能力,常用於製作治療藥水,特別是用於治療深層傷口。'),
Document(page_content='曼德珍珠奶茶草:這種植物具有強大的魔法屬性,常用於恢復被石化的受害者。')],
'answer': '🐐💧️\n\n有以下幾種工具可以使用:\n\n* 山羊可愛蓮花石:可以解百毒,對於急性中毒非常有效。\n*
日本小可愛佐籐鱗片:具有強大的治愈能力,可以用於製作治療藥水,特別是深層傷口的治療。\n*
曼德珍珠奶茶草:具有強大的魔法屬性,常用於恢復被石化的受害者。\n\n這些工具都可以幫助你解決問題! 💪️'}\n這些工具都可以幫助你解決問題! 💪️'}
實作教學2
langchain_rag_pdf.py >> 這個_pdf代表是匯入pdf檔案
把前面建立模型和文件的程式碼,更改為以下
# 初始化Ollama模型
llm = Ollama(model='llama3')
# 載入並分割PDF文件
loader = PyPDFLoader("文件名稱.pdf")
docs = loader.load_and_split()
本文是使用PyPDFLoader來讀入PDF,LangChain中還有很多其他的API,可以參考官方文獻。官方文獻。
Demo
本文有在GitHub放了我寫的PDF測試檔案叫做pdf_test.pdf,大家也可以拿來測試用。
loader = PyPDFLoader("pdf_test.pdf")
root@4be643ba6a94:/app# python3 langchain_rag_pdf.py
>>> 請給我50字的摘要
🇨🇳
Wei tsung chang 的簡介:碩士畢業、AI軟體工程師,熱心工作,喜歡撰寫教學文章。他的技術栈包括Python、JavaScript、C#、Kotlin等程式語言,以及 Git 版本控制、Docker 等知識。
(Translation: Introduction to Wei tsung chang: Master's degree holder, AI software engineer, enthusiastic about work, likes writing tutorial articles. His technical stack includes programming languages such as Python, JavaScript, C#, Kotlin, and version control tools like Git.)🇨🇳
>>> 文件中軟體工程師的名字叫什麼?
🤔
Answer: Wei Tsung Chang 碩士畢業,同樣可以稱呼為 Weiberson。
(The software engineer's name is Wei Tsung Chang, and can also be called Weiberson.)
print(response)
print(response) 也就是把retrieval_chain.invoke給print出來,可以讓大家更清楚RAG所生成東西的架構。
{'input': '這篇pdf在說什麼?',
'context':
[Document(page_content='全部的PDF文字都會顯示在這裡',
metadata={'source': 'weibert.pdf', 'page': 0})],
'answer': 'LLM給的答案會顯示在這裡.'}
References
https://huggingface.co/learn/cookbook/zh-CN/advanced_rag
https://chatgpt.com/share/e0f169d7-8620-4468-ba0a-581e7d9f5676
https://medium.com/@jackcheang5/%E5%BB%BA%E6%A7%8B%E7%B0%A1%E6%98%93rag%E7%B3%BB%E7%B5%B1-ca4e593f3fed
https://www.linkedin.com/pulse/beginners-guide-retrieval-chain-using-langchain-vijaykumar-kartha-kuinc?trk=article-ssr-frontend-pulse_little-text-block
https://myapollo.com.tw/blog/langchain-tutorial-retrieval/
喜歡 好崴寶 Weibert Weiberson 的文章嗎?在這裡留下你的評論!本留言區支援 Markdown 語法。
