

RAG 中文本分割:chunk_size 和 chunk_overlap 設定指南
日期:2024-11-29
大型文檔需要分割為多個較小的文本塊,以便向量檢索和生成模型更高效地處理。分割過程中的關鍵參數是 chunk_size 和 chunk_overlap,這兩者對檢索效率和結果準確性有直接影響。
文本分割的重要性:
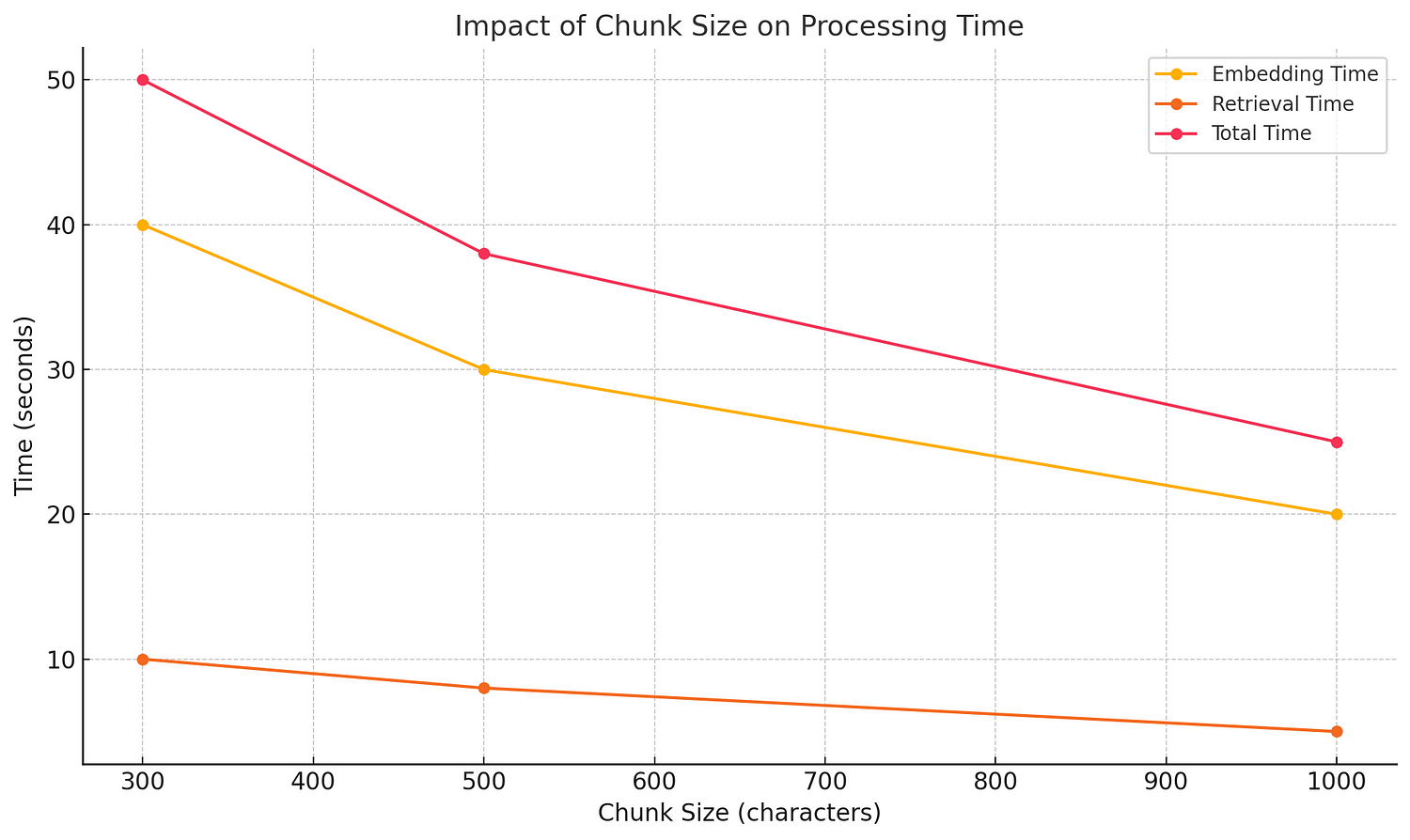
通常情況下,chunk_size(文本塊大小)設置得更大,處理總時間會減少,但這取決於處理的具體步驟以及應用場景。
1. chunk_size 大小對時間的影響
文本分割時間
- 當 chunk_size 設置較大時,文檔會被分割成較少的塊,因此分割所需的時間通常會減少。
- 例如:
- 文檔總長為 10,000 字符:
chunk_size=500會生成 20 個文本塊。chunk_size=1000只需生成 10 個文本塊。
- 文檔總長為 10,000 字符:
- 例如:
- 減少文本塊數量能降低分割處理的時間成本。
嵌入向量計算時間
- 向量計算時間與生成的文本塊數量直接相關:
- 小 chunk_size:需生成更多文本塊,每塊需單獨計算嵌入,總時間較長。
- 大 chunk_size:生成的文本塊數量減少,嵌入計算次數也相應減少,縮短總時間。
注意: 當每塊內容過大時,單塊處理時間會增加,但整體速度仍優於小塊分割。
檢索和生成時間
- 在檢索過程中,較少的文本塊會使向量數據庫檢索速度更快。
- 生成過程中,檢索結果量減少,有助於縮短生成回答的時間。
2. chunk_size 大小的限制
上下文完整性
- chunk_size 過大:每個文本塊包含的信息可能過於多樣化,降低檢索的針對性。
- 可能導致生成的回答不夠準確,因為檢索上下文與查詢可能不相關。
模型輸入限制
- 大多數生成式模型(如 GPT、LLaMA)對輸入 Token 數量有限制(通常是
1024至4096Tokens)。
chunk_size 過大 時,單塊內容可能超出 Token 限制,需進一步切分,增加處理步驟。
語義連續性
- 當 chunk_overlap 設置較小且 chunk_size 過大時,相鄰文本塊之間的語義關聯可能減弱,導致檢索結果不連貫。
最佳實踐建議
1. chunk_size 的合理範圍
- 建議 chunk_size 在
500至1000字符之間,以兼顧語義連續性與處理速度。 - 如果文檔段落相對獨立,可適當增大 chunk_size(如
1000–1500字符)。
2. chunk_overlap 的調整
- 當 chunk_size 增大 時,可適當減少 chunk_overlap:
- 設置為 chunk_size 的
5%-10%。
- 設置為 chunk_size 的
- 如果上下文高度相關,則增加 chunk_overlap 至
20%-30%。
3. 根據文檔特性調整
- 文檔結構清晰(如 FAQ 或技術手冊):可選擇較大的 chunk_size。
- 文檔包含複雜上下文(如學術文章或小說):適當減小 chunk_size 並增加 chunk_overlap。
極端情況的風險分析
chunk_size 過大
- 優點:減少處理時間。
- 風險:檢索針對性下降,生成結果可能與查詢無關。
chunk_size 過小
- 優點:上下文相關性更高。
- 風險:計算成本激增,檢索速度大幅降低。
chunk_overlap 過大
- 優點:語義連續性好。
- 風險:重疊部分過多導致處理冗餘,增加檢索和生成負擔。
chunk_overlap 過小
- 優點:減少計算資源需求。
- 風險:語義斷裂,導致檢索和生成結果不連貫。
崴寶總結
在 RAG 框架中文本分割的設置直接影響檢索和生成的效率與質量。選擇合適的 chunk_size 和 chunk_overlap,結合工具(如 LangChain)的自動化分割功能,能進一步簡化操作。
小結: 只需少量調整,即可顯著提升 RAG 系統的檢索效率與生成準確性。
喜歡 好崴寶 Weibert Weiberson 的文章嗎?在這裡留下你的評論!本留言區支援 Markdown 語法。
